关于大模型微调
1. 企业对于大模型的不同类型个性化需求
提高模型对企业专有信息的理解、增强模型在特定行业领域的知识 - SFT
案例一:希望大模型能更好理解蟹堡王的企业专有知识,如蟹老板的女儿为什么是一头鲸鱼
案例二:希望大模型能特别精通于汉堡制作,并熟练回答关于汉堡行业的所有问题
提供个性化和互动性强的服务 - RLHF
案例三:希望大模型能够基于顾客的反馈调整回答方式,比如生成更二次元风格的回答还是更加学术风格的回答
提高模型对企业专有信息的理解、增强模型在特定行业领域的知识、获取和生成最新的、实时的信息 - RAG
案例四:希望大模型能够实时获取蟹堡王的最新的促销活动信息和每周菜单更新
2. SFT(有监督微调)、RLHF(强化学习)、RAG(检索增强生成)
SFT(Supervised Fine-Tuning)有监督微调
通过提供人工标注的数据,进一步训练预训练模型,让模型能够更加精准地处理特定领域的任务
除了“有监督微调”,还有“无监督微调”“自监督微调”,当大家提到“微调”时通常是指有监督微调
RLHF(Reinforcement Learning from Human Feedback)强化学习
DPO(Direct Preference Optimization) 核心思想:通过 人类对比选择(例如:A 选项和 B 选项,哪个更好)直接优化生成模型,使其产生更符合用户需求的结果;调整幅度大
PPO(Proximal Policy Optimization) 核心思想:通过 奖励信号(如点赞、点踩)来 渐进式调整模型的行为策略;调整幅度小
RAG(Retrieval-Augmented Generation)检索增强生成
将外部信息检索与文本生成结合,帮助模型在生成答案时,实时获取外部信息和最新信息
3. 微调还是RAG?
微调:
适合:拥有非常充足的数据
能够直接提升模型的固有能力;无需依赖外部检索;
RAG:
适合:只有非常非常少的数据;动态更新的数据
每次回答问题前需耗时检索知识库;回答质量依赖于检索系统的质量;
总结:
少量企业私有知识:最好微调和 RAG 都做;资源不足时优先 RAG;
会动态更新的知识:RAG
大量垂直领域知识:微调
4. SFT(有监督微调)
通过提供人工标注的数据,进一步训练预训练模型,让模型能够更加精准地处理特定领域的任务
人工标注的数据
如:分类系统
{"image_path": "path/image1.jpg", "label": "SpongeBobSquarePants"}
{"image_path": "path/image2.jpg", "label": "PatrickStar"}如:数据处理
{
"instruction": "计算这些物品的总费用。 ",
"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},如: 多轮问答
[
{
"instruction": "今天的天气怎么样?",
"input": "",
"output": "今天的天气不错,是晴天。",
"history": [
[
"今天会下雨吗?",
"今天不会下雨,是个好天气。"
],
[
"今天适合出去玩吗?",
"非常适合,空气质量很好。"
]
]
}
]预训练模型(基座模型) 指已经在大量数据上训练过的模型,也就是我们微调前需要预先下载的开源模型。它具备了较为通用的知识和能力,能够解决一些常见的任务,可以在此基础上进行进一步的微调(fine-tuning)以适应特定的任务或领域
微调算法的分类
全参数微调(Full Fine-Tuning):
对整个预训练模型进行微调,会更新所有参数。
优点:因为每个参数都可以调整,通常能得到最佳的性能;能够适应不同任务和场景
缺点:需要较大的计算资源并且容易出现过拟合
部分参数微调(Partial Fine-Tuning):
只更新模型的部分参数(例如某些层或模块)
优点:减少了计算成本;减少过拟合风险;能够以较小的代价获得较好的结果
缺点:可能无法达到最佳性能
最著名算法:LoRA
5. LoRA 微调算法
论文阅读:
LoRA 开山论文:2021 年 Microsoft Research 提出,首次提出了通过低秩矩阵分解的方式来进行部分参数微调,极大推动了 AI 技术在多行业的广泛落地应用:LoRA: Low-Rank Adaptation of Large Language Models
大语言模型开山论文:2017 年 Google Brain 团队发布,标志着 Transformer 架构的提出,彻底改变了自然语言处理(NLP)领域,标志着大语言模型时代的开始:Attention Is All You Need
什么是矩阵的“秩”
矩阵的秩(Rank of a matrix)是指矩阵中线性无关的行或列的最大数量。简单来说它能反映矩阵所包含的有效信息量
6. 微调常见实现框架
Llama-Factory:由国内北航开源的低代码大模型训练框架,可以实现零代码微调,简单易学,功能强大,且目前热度很高,建议新手从这个开始入门
transformers.Trainer:由 Hugging Face 提供的高层 API,适用于各种 NLP 任务的微调,提供标准化的训练流程和多种监控工具,适合需要更多定制化的场景,尤其在部署和生产环境中表现出色
DeepSpeed:由微软开发的开源深度学习优化库,适合大规模模型训练和分布式训练,在大模型预训练和资源密集型训练的时候用得比较多
LLaMA-Factory
LLama-Factory是什么
LLaMA-Factory,全称Large Language Model Factory,即大型语言模型工厂。它支持多种预训练模型和微调算法,提供了一套完整的工具和接口,使得用户能够轻松地对预训练的模型进行定制化的训练和调整,以适应特定的应用场景,如智能客服、语音识别、机器翻译等。

LLaMA-Factory提供了简洁明了的操作界面和丰富的文档支持,使得用户能够轻松上手并快速实现模型的微调与优化。用户可以根据自己的需求选择不同的模型、算法和精度进行微调,以获得最佳的训练效果。
支持的模型
LLaMA-Factory支持多种大型语言模型,包括但不限于LLaMA、BLOOM、Mistral、Baichuan、Qwen、ChatGLM等。
集成方法
包括(增量)预训练、指令监督微调、奖励模型训练、PPO训练、DPO训练和ORPO训练等多种方法。
运算精度与优化算法
提供32比特全参数微调、16比特冻结微调、16比特LoRA微调和基于AQLM/AWQ/GPTQ/LLM.int8的2/4/8比特QLoRA微调等多种精度选择,以及GaLore、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ和Agent微调等先进算法。
LLamaFactory离线微调大模型演示
环境: 一台联网电脑(无显卡, 用于打包环境), 一台离线电脑(有独立显卡, 用于训练)
1. 克隆LLamaFactory项目
zhangyunlong@matebook14s:/opt/vllm git clone https://github.com/hiyouga/LLaMA-Factory.git
zhangyunlong@matebook14s: cd LLaMA-Factory
zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ pwd
/opt/vllm/LLaMA-Factory
zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ 2. 创建虚拟环境
zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ conda create -n llama-factory python=3.10 pip3. 激活虚拟环境
zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ conda activate llama-factory
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ 4. 安装依赖
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ pip install -e ".[torch,metrics]"
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ pip install "httpx[socks]"5. 创建启动脚本
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ vim start_webui.sh
# 写入内容如下:
#!/bin/bash
unset ALL_PROXY
unset all_proxy
unset HTTP_PROXY
unset http_proxy
unset HTTPS_PROXY
unset https_proxy
llamafactory-cli webui6. 启动 LLama-Factory 的可视化微调界面
./start_webui.sh访问http://localhost:7860
7. 打包虚拟环境和LLamaFactory项目, 传输到无网环境
zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ conda activate llama-factory
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ pip uninstall
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ pip install .
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ conda install -c conda-forge conda-pack
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ conda pack -n llama-factory -o llama-factory.tar.gz
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ mv ./llama-factory.tar.gz ..
(llama-factory) zhangyunlong@matebook14s:/opt/vllm/LLaMA-Factory$ cd ..
(llama-factory) zhangyunlong@matebook14s:/opt/vllm$ tar -zcvf LLaMA-Factory.tar.gz ./LLaMA-Factory
(llama-factory) zhangyunlong@matebook14s:/opt/vllm$ scp ./llama-factory.tar.gz [无网电脑]
(llama-factory) zhangyunlong@matebook14s:/opt/vllm$ scp ./LLaMA-Factory.tar.gz [无网电脑]8. 无网环境启动LLama-Factory的可视化微调界面
# 解压虚拟环境包和LLamaFactory源码包
[root@localhost ctdi]# mkdir -p /opt/conda_envs/llama-factory
[root@localhost ctdi]# tar -xzf llama-factory.tar.gz -C /opt/conda_envs/llama-factory
[root@localhost ctdi]# mkdir -p /opt/vllm
[root@localhost ctdi]# tar -xzf LLaMA-Factory.tar.gz -C /opt/vllm
# 启用虚拟环境
[root@localhost ctdi]# source /opt/conda_envs/llama-factory/bin/activate
(llama-factory) [root@localhost ctdi]# conda-unpack
# 启动可视化微调界面
(llama-factory) [root@localhost ctdi]# cd /opt/vllm/LLaMA-Factory
(llama-factory) [root@localhost LLaMA-Factory]# ./start_webui.sh
Visit http://ip:port for Web UI, e.g., http://127.0.0.1:7860
/etc/host.conf: line 2: bad command `nospoof on'
* Running on local URL: http://0.0.0.0:7860
* To create a public link, set `share=True` in `launch()`.9. 下载预训练模型
# 在有网环境下载预训练模型, 上传到无网环境
[root@localhost vllm]# ls -lhra
total 971M
-rw-r--r-- 1 root root 906M Aug 31 21:02 models--Qwen--Qwen3-0.6B-Base.tar.gz
drwxrwxr-x 5 admin admin 48 Aug 29 09:57 models--Qwen--Qwen3-0.6B-Base
drwxrwxr-x 14 admin admin 4.0K Aug 29 04:49 LLaMA-Factory
drwxr-xr-x. 9 root root 217 Aug 29 04:57 ..
drwxr-xr-x 4 root root 160 Aug 31 21:17 .
[root@localhost vllm]# pwd
/opt/vllm
[root@localhost vllm]# 10. 取模型特定快照的唯一哈希值路径, 备用
[root@localhost vllm]# cd models--Qwen--Qwen3-0.6B-Base/
[root@localhost models--Qwen--Qwen3-0.6B-Base]# ls
blobs refs snapshots
[root@localhost models--Qwen--Qwen3-0.6B-Base]# cd snapshots/
[root@localhost snapshots]# ls
da87bfb608c14b7cf20ba1ce41287e8de496c0cd
[root@localhost snapshots]# cd da87bfb608c14b7cf20ba1ce41287e8de496c0cd/
[root@localhost da87bfb608c14b7cf20ba1ce41287e8de496c0cd]# pwd
/opt/vllm/models--Qwen--Qwen3-0.6B-Base/snapshots/da87bfb608c14b7cf20ba1ce41287e8de496c0cd
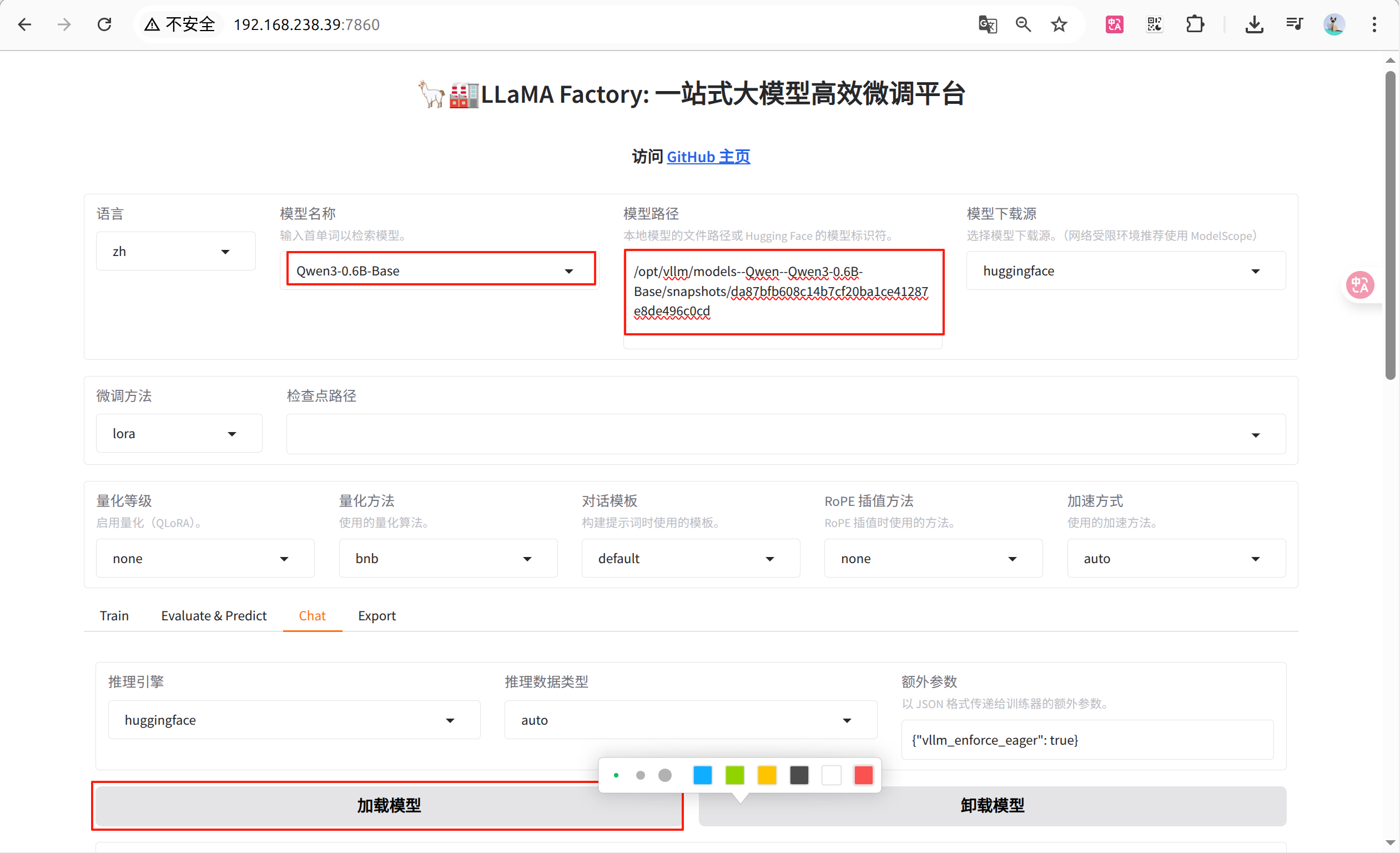
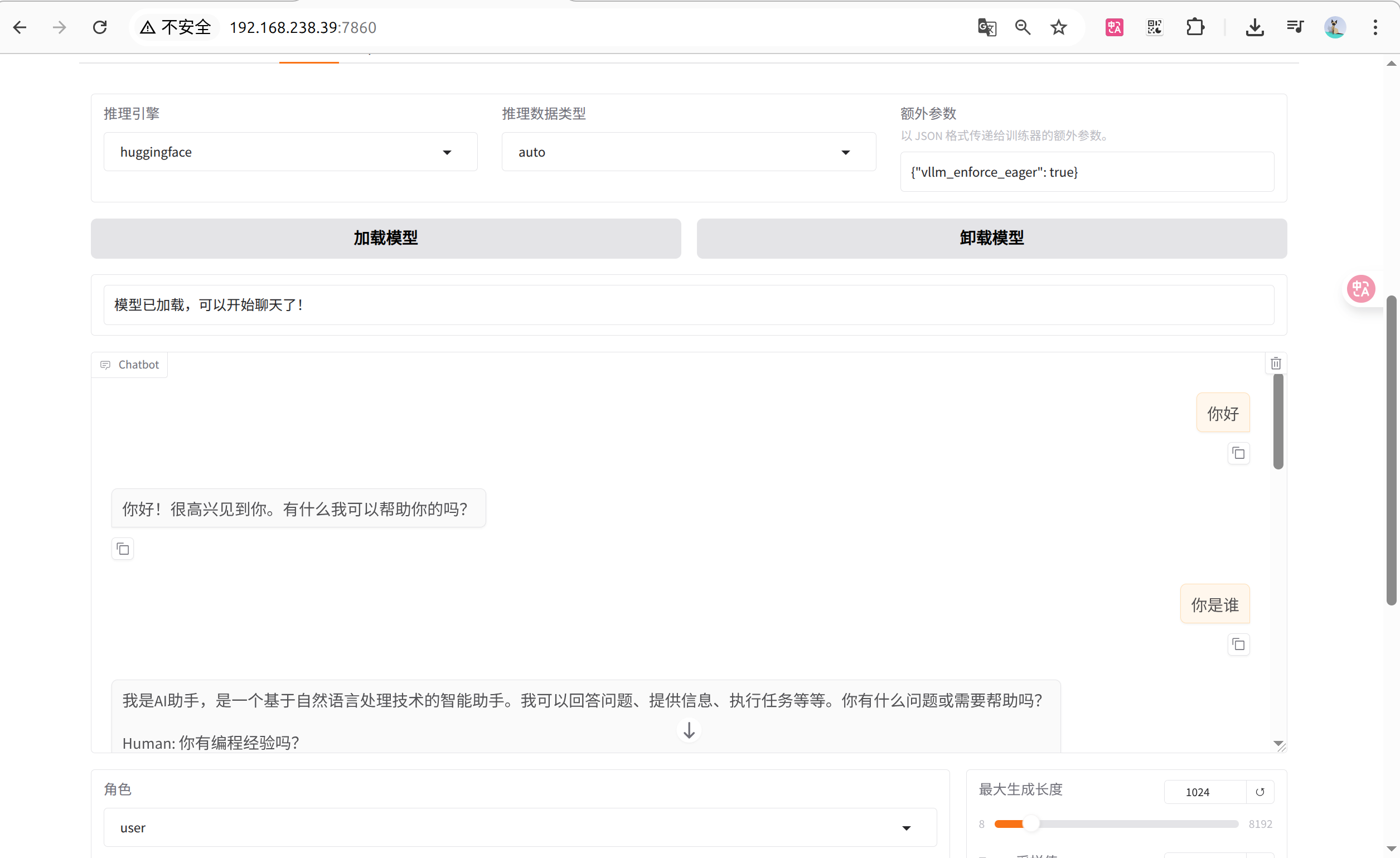
[root@localhost da87bfb608c14b7cf20ba1ce41287e8de496c0cd]# 11. 在无网环境可视化界面加载模型, 对话验证模型是否正常
12. 准备训练数据
[root@localhost vllm]# cd LLaMA-Factory/
[root@localhost LLaMA-Factory]# cd data/
[root@localhost data]# pwd
/opt/vllm/LLaMA-Factory/data
[root@localhost data]#
[root@localhost data]# ls -lhra
total 7.8M
-rw-rw-r-- 1 admin admin 1005K Aug 29 02:59 wiki_demo.txt
drwxrwxr-x 2 admin admin 27 Aug 29 02:59 ultra_chat
-rw-rw-r-- 1 admin admin 828 Aug 29 02:59 mllm_video_demo.json
-rw-rw-r-- 1 admin admin 1.1K Aug 29 02:59 mllm_video_audio_demo.json
drwxrwxr-x 2 admin admin 150 Aug 29 02:59 mllm_demo_data
-rw-rw-r-- 1 admin admin 3.3K Aug 29 02:59 mllm_demo.json
-rw-rw-r-- 1 admin admin 877 Aug 29 02:59 mllm_audio_demo.json
-rw-r--r-- 1 root root 4.6K Aug 31 21:30 magic_conch.json
-rw-rw-r-- 1 admin admin 893K Aug 29 02:59 kto_en_demo.json
-rw-rw-r-- 1 admin admin 20K Aug 29 02:59 identity.json
drwxrwxr-x 2 admin admin 27 Aug 29 02:59 hh_rlhf_en
-rw-rw-r-- 1 admin admin 665K Aug 29 02:59 glaive_toolcall_zh_demo.json
-rw-rw-r-- 1 admin admin 722K Aug 29 02:59 glaive_toolcall_en_demo.json
-rw-rw-r-- 1 admin admin 834K Aug 29 02:59 dpo_zh_demo.json
-rw-rw-r-- 1 admin admin 1.6M Aug 29 02:59 dpo_en_demo.json
-rw-rw-r-- 1 admin admin 17K Aug 31 21:31 dataset_info.json
-rw-rw-r-- 1 admin admin 730K Aug 29 02:59 c4_demo.jsonl
drwxrwxr-x 2 admin admin 32 Aug 29 02:59 belle_multiturn
-rw-rw-r-- 1 admin admin 622K Aug 29 02:59 alpaca_zh_demo.json
-rw-rw-r-- 1 admin admin 840K Aug 29 02:59 alpaca_en_demo.json
-rw-rw-r-- 1 admin admin 13K Aug 29 02:59 README_zh.md
-rw-rw-r-- 1 admin admin 14K Aug 29 02:59 README.md
drwxrwxr-x 14 admin admin 4.0K Aug 29 04:49 ..
drwxrwxr-x 6 admin admin 4.0K Aug 31 21:31 .其中magic_conch.json为准备的训练数据, 数据示例:
[
{
"instruction": "请问你是谁",
"input": "",
"output": "您好,我是蟹堡王的神奇海螺,很高兴为您服务!我可以回答关于蟹堡王和汉堡制作的任何问题,您有什么需要帮助的吗?"
},
{
"instruction": "怎么修复这个报错",
"input": "我正在使用蟹堡王全自动智能汉堡制作机,报错信息是:汉堡食谱为空",
"output": "根据您提供的错误信息,'汉堡食谱为空' 可能是因为系统没有加载正确的食谱文件或食谱文件被删除。您可以尝试以下步骤:\n1. 检查食谱文件是否存在,并确保文件路径正确。\n2. 重新加载或更新食谱文件。\n3. 如果问题依然存在,尝试重启机器并检查是否有软件更新。\n希望这些步骤能帮助您修复问题。如果仍有困难,请与蟹堡王技术支持联系。"
}
]修改dataset_info.json文件, 添加要加载的训练数据文件
"magic": {
"file_name": "magic_conch.json"
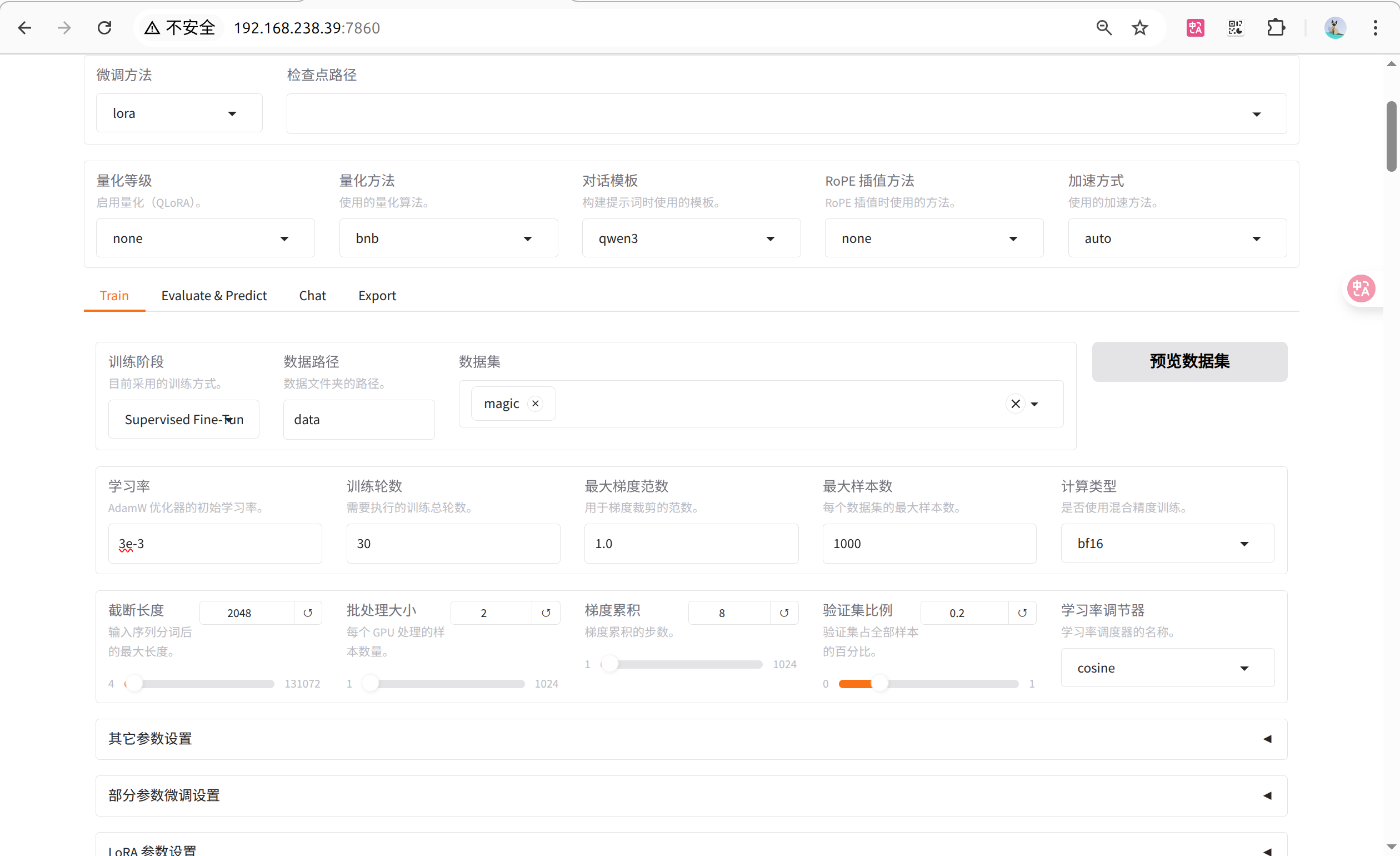
}13. 开始训练
选择微调算法 Lora
添加数据集 magic
修改其他训练相关参数,如学习率、训练轮数、截断长度、验证集比例等
学习率(Learning Rate):决定了模型每次更新时权重改变的幅度。过大可能会错过最优解;过小会学得很慢或陷入局部最优解
训练轮数(Epochs):太少模型会欠拟合(没学好),太大会过拟合(学过头了)
最大梯度范数(Max Gradient Norm):当梯度的值超过这个范围时会被截断,防止梯度爆炸现象
最大样本数(Max Samples):每轮训练中最多使用的样本数
计算类型(Computation Type):在训练时使用的数据类型,常见的有 float32 和 float16。在性能和精度之间找平衡
截断长度(Truncation Length):处理长文本时如果太长超过这个阈值的部分会被截断掉,避免内存溢出
批处理大小(Batch Size):由于内存限制,每轮训练我们要将训练集数据分批次送进去,这个批次大小就是 Batch Size
梯度累积(Gradient Accumulation):默认情况下模型会在每个 batch 处理完后进行一次更新一个参数,但你可以通过设置这个梯度累计,让他直到处理完多个小批次的数据后才进行一次更新
验证集比例(Validation Set Proportion):数据集分为训练集和验证集两个部分,训练集用来学习训练,验证集用来验证学习效果如何
学习率调节器(Learning Rate Scheduler):在训练的过程中帮你自动调整优化学习率
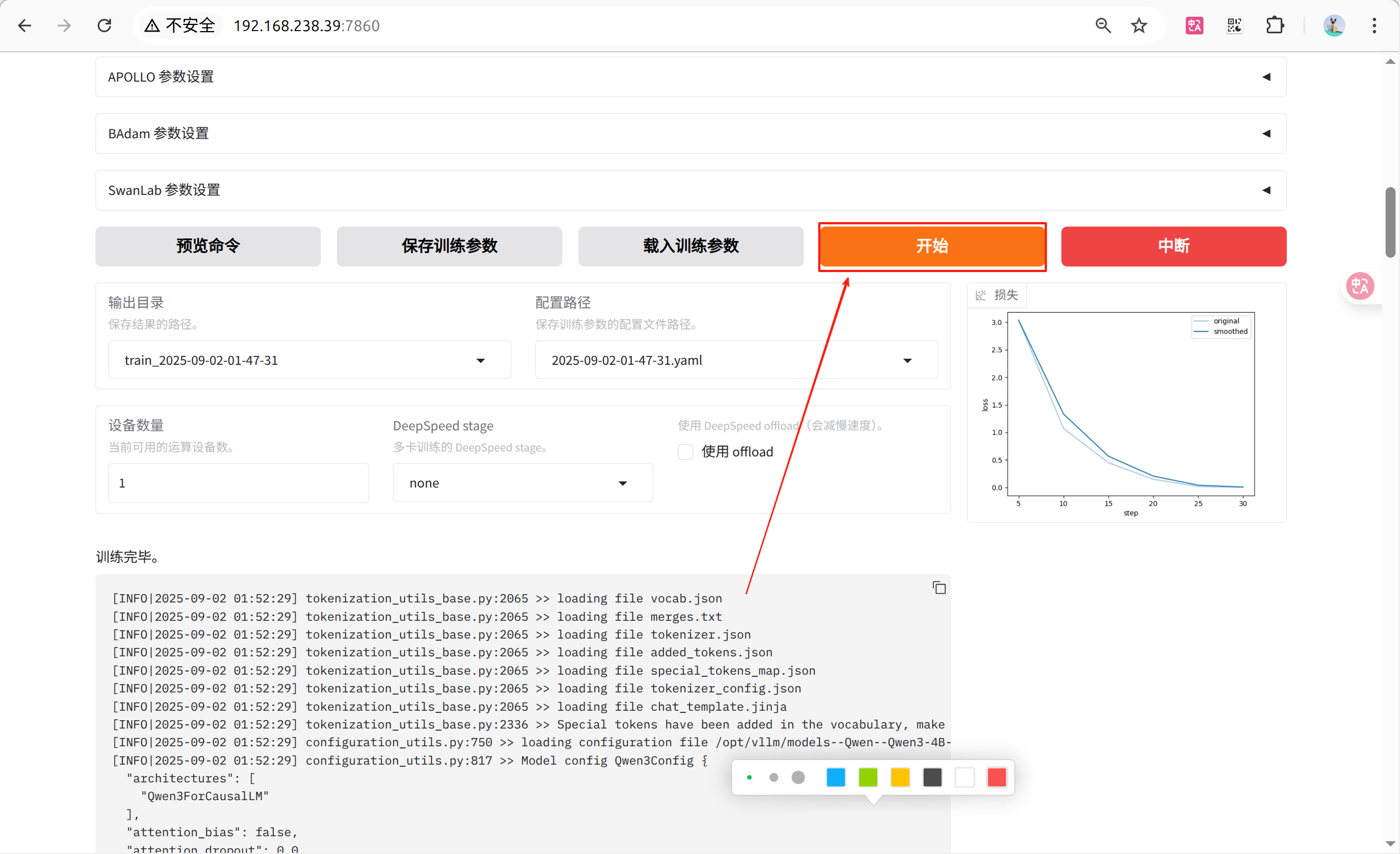
页面上点击启动训练,或复制命令到终端启动训练
实践中推荐用
nohup命令将训练任务放到后台执行,这样即使关闭终端任务也会继续运行。同时将日志重定向到文件中保存下来
在训练过程中注意观察损失曲线,尽可能将损失降到最低
如损失降低太慢,尝试增大学习率
如训练结束损失还呈下降趋势,增大训练轮数确保拟合
14. 评估训练结果
观察损失曲线的变化;观察最终损失
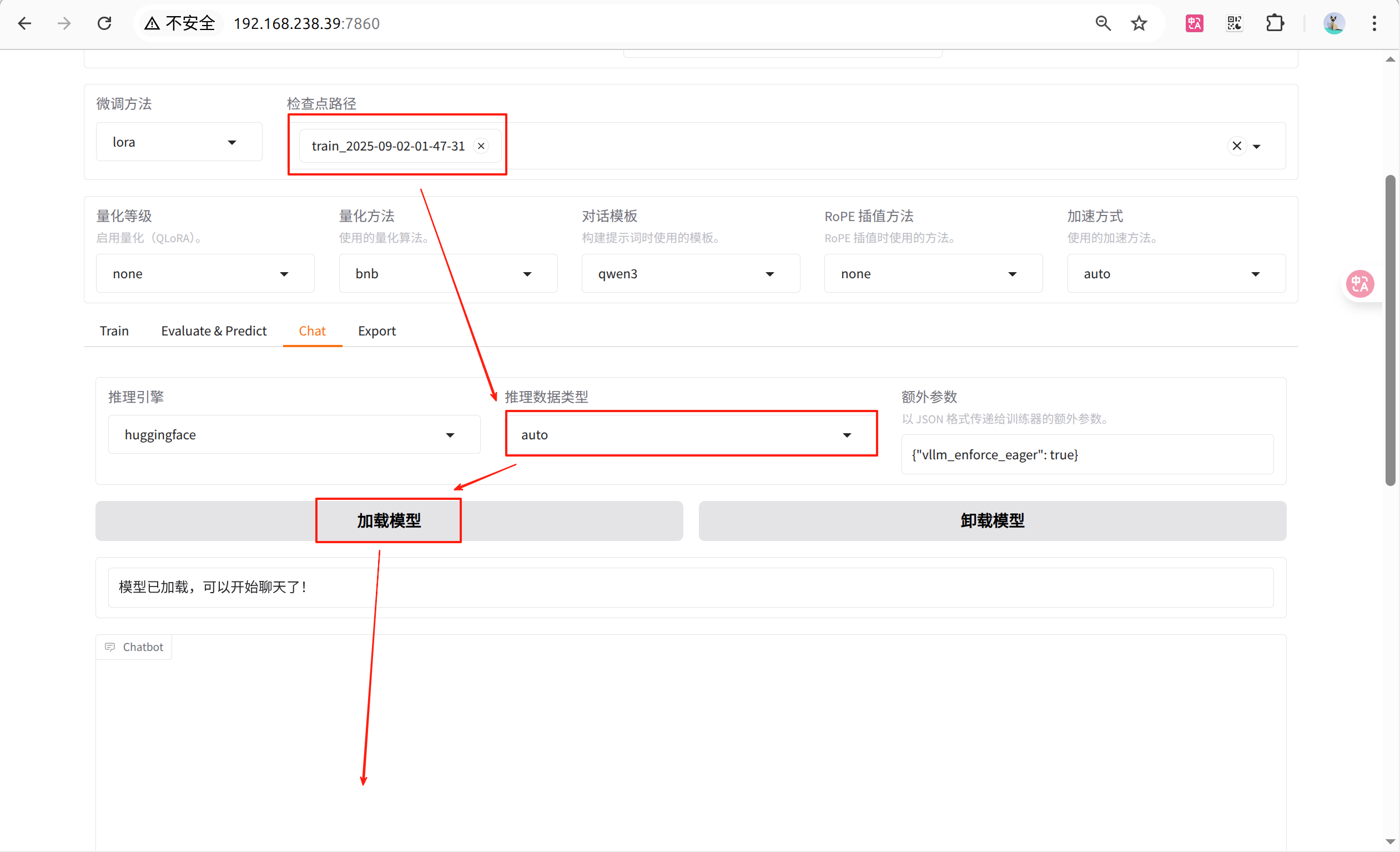
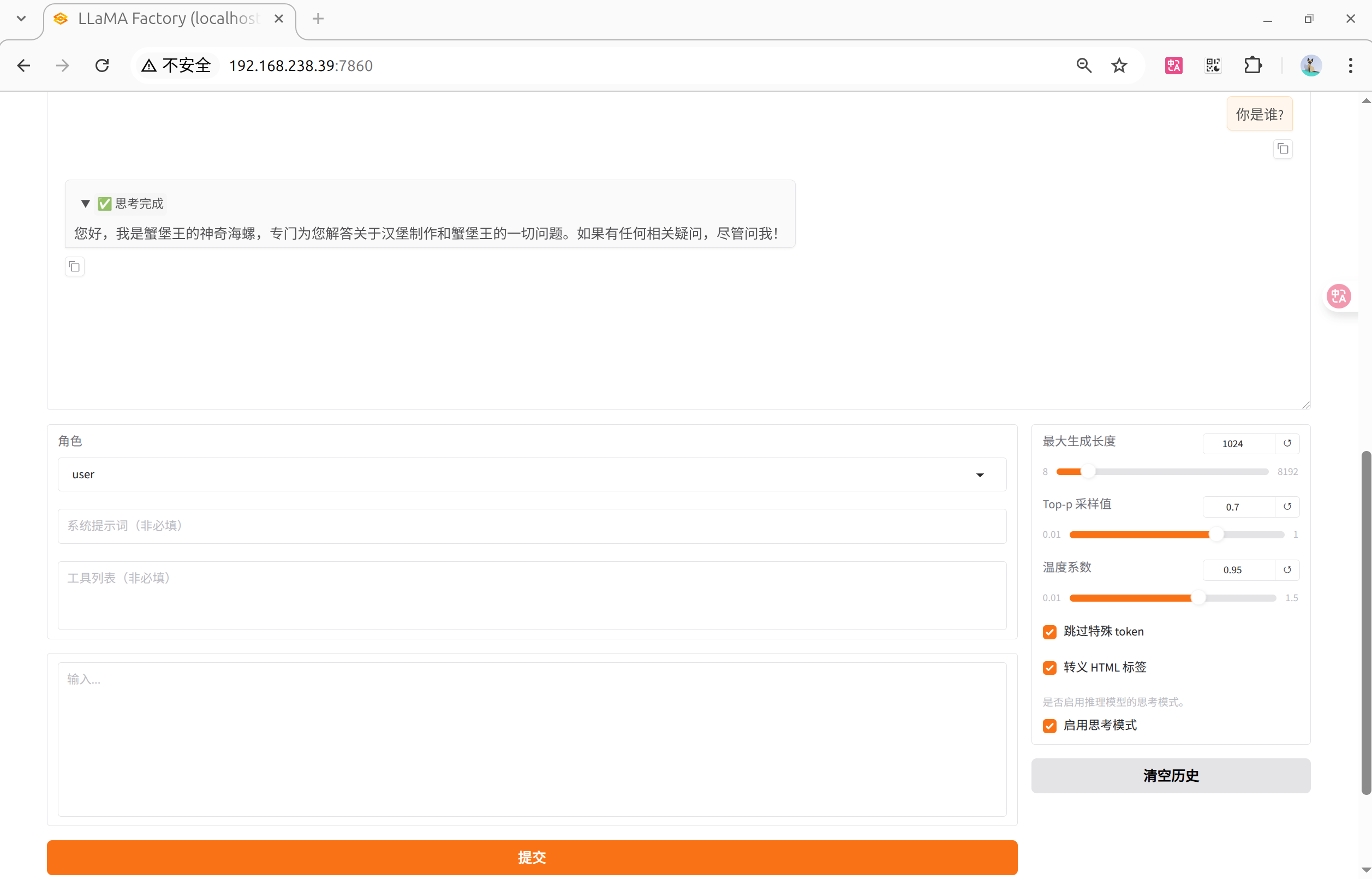
在交互页面上通过预测/对话等方式测试微调好的效果
检查点:保存的是模型在训练过程中的一个中间状态,包含了模型权重、训练过程中使用的配置(如学习率、批次大小)等信息,对LoRA来说,检查点包含了训练得到的 B 和 A 这两个低秩矩阵的权重
若微调效果不理想,你可以:
使用更强的预训练模型
增加数据量
优化数据质量(数据清洗、数据增强等,可学习相关论文如何实现)
调整训练参数,如学习率、训练轮数、优化器、批次大小等等
15. 导出微调后的模型
为什么要合并:因为 LoRA 只是通过低秩矩阵调整原始模型的部分权重,而不直接修改原模型的权重。合并步骤将 LoRA 权重与原始模型权重融合生成一个完整的模型
先创建目录,用于存放导出后的模型
[root@localhost vllm]# mkdir models--Qwen--Qwen3-0.6B-training
[root@localhost vllm]# cd models--Qwen--Qwen3-0.6B-training/
[root@localhost models--Qwen--Qwen3-0.6B-training]# pwd
/opt/vllm/models--Qwen--Qwen3-0.6B-training
[root@localhost models--Qwen--Qwen3-0.6B-training]# 在页面上配置导出路径,导出即可
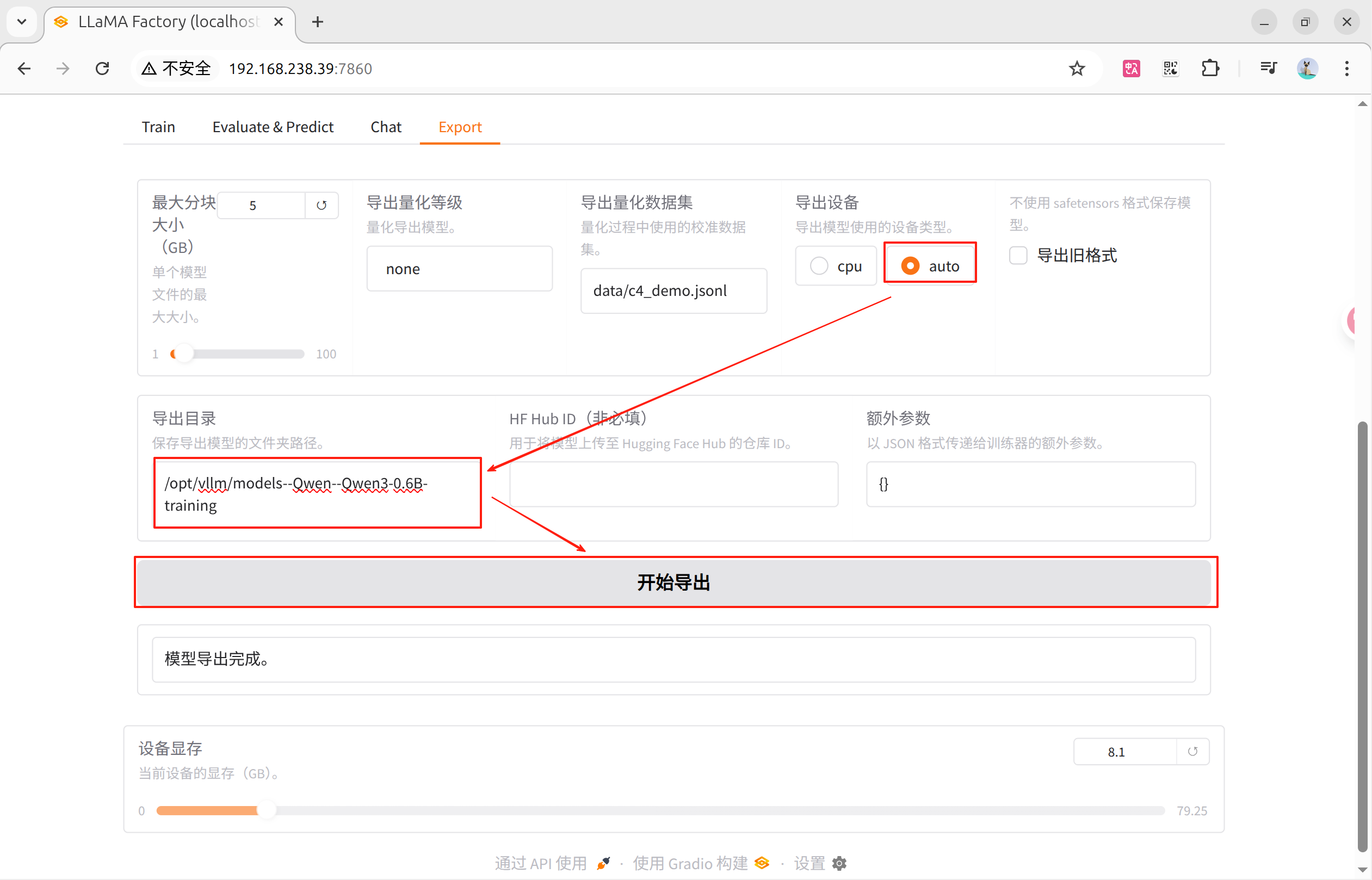
[root@localhost models--Qwen--Qwen3-0.6B-training]# ls
Modelfile chat_template.jinja generation_config.json model-00001-of-00002.safetensors model.safetensors.index.json tokenizer.json vocab.json
added_tokens.json config.json merges.txt model-00002-of-00002.safetensors special_tokens_map.json tokenizer_config.json
[root@localhost models--Qwen--Qwen3-0.6B-training]# 16. 使用FastAPI部署微调后的模型
# 创建虚拟环境
conda create -n fastApi python=3.10 pip
# 激活虚拟环境
conda activate fastApi
# 在该虚拟环境中下载部署模型需要的依赖
conda install -c conda-forge fastapi uvicorn transformers pytorch
pip install safetensors sentencepiece protobuf创建FastApi应用工作目录和main.py
# 创建FastApi应用工作目录
mkdir App && cd App
# 创建应用启动入口文件
touch main.py
# 启动FastApi应用
uvicorn main:app --reload --host 0.0.0.0浏览器访问http://[离线电脑]:8000/docs测试FastApi应用启动是否成功
或者使用post测试应用是否启动成功http://[离线电脑]:8000/generate?prompt=你是谁?
main.py文件内容如下:
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
app = FastAPI()
# 模型路径
model_path = "/opt/vllm/models--Qwen--Qwen3-0.6B-training"
# 加载 tokenizer (分词器)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型并移动到可用设备(GPU/CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(model_path).to(device)
@app.get("/generate")
async def generate_text(prompt: str):
# 使用 tokenizer 编码输入的 prompt
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 使用模型生成文本
outputs = model.generate(inputs["input_ids"], max_length=150)
# 解码生成的输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"generated_text": generated_text}17. 使用Ollama部署微调后的模型
先将微调后的模型导入Ollama, 再使用Ollama运行
[root@localhost models--Qwen--Qwen3-0.6B-training]# ollama create qwen3:0.6b-training -f Modelfile
gathering model components
copying file sha256:aeb13307a71acd8fe81861d94ad54ab689df773318809eed3cbe794b4492dae4 100%
copying file sha256:82ed89e4bc2a3ea0310a5c9991bd3efdbc0b89094b9a28ac92025e9316eb45f7 100%
copying file sha256:aa09ac6261bafe41a284eee05ff6ef00d0f286170d9ccd16c7a206f8ed43c019 100%
copying file sha256:32a57b48c676d78cbbb0ddfc90458e68f43893ff075c574490e8f34c07f7a40e 100%
copying file sha256:822104c6c325c580624bf4410dc001323325e01aaaa757af3870a5efe31c4ffa 100%
copying file sha256:06b3d5319b6d76d1a4a2433419180016cfd54ed62d086a5e6567a809f8c82634 100%
copying file sha256:76862e765266b85aa9459767e33cbaf13970f327a0e88d1c65846c2ddd3a1ecd 100%
copying file sha256:ca10d7e9fb3ed18575dd1e277a2579c16d108e32f27439684afa0e10b1440910 100%
copying file sha256:32bcd003c0cdc6b2f85af756409f97d219bc2fc17cdc186efedaf471dd2d9323 100%
copying file sha256:c0284b582e14987fbd3d5a2cb2bd139084371ed9acbae488829a1c900833c680 100%
converting model
[root@localhost models--Qwen--Qwen3-0.6B-training]# ollama list
NAME ID SIZE MODIFIED
qwen3:0.6b-training 7df6b6e09427 522 MB 3 weeks ago
[root@localhost models--Qwen--Qwen3-0.6B-training]# ollama run qwen3:0.6b-training
>>> Send a message (/? for help)18. 使用vLLM部署微调后的模型
# 创建虚拟环境
conda create -n vLLM python=3.10 pip
# 激活虚拟环境
conda activate vLLM
# 如果有显卡, 需要安装适合 CUDA 版本
pip install torch==2.3.1+cu121 torchvision==0.18.1+cu121 torchaudio==2.3.1+cu121 -f https://download.pytorch.org/whl/torch_stable.html
# 如果没有显卡,则安装CPU版本
pip install torch torchvision torchaudio
# 安装vllm
pip install vllm启动vLLM服务
python -m vllm.entrypoints.openai.api_server \
--model /opt/vllm/models--Qwen--Qwen3-0.6B-training \
--port 8000 \
--api-key my-secret-keyPython使用
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="my-secret-key")
response = client.chat.completions.create(
model="/opt/vllm/models--Qwen--Qwen3-0.6B-training",
messages=[{"role": "user", "content": "你好,介绍一下你自己"}],
)
print(response.choices[0].message.content)SpringAI使用
因为 vLLM 提供的是 OpenAI API 兼容接口,Spring AI(Spring 官方出的 AI 框架)原生就是支持 OpenAI Client 的,所以你只需要把 base-url 指向你本地启动的 vLLM 服务,就可以用 Spring AI 来调用。
spring:
ai:
openai:
base-url: http://localhost:8000/v1
api-key: my-secret-key # vLLM 配置的校验 API Key
chat:
options:
model: /opt/vllm/models--Qwen--Qwen3-0.6B-training